
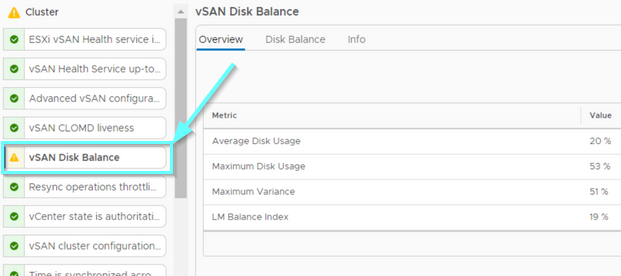
If you use a vSAN in your environment you will probably some day experience errors in the Skyline Health Check that indicate your cluster is imbalanced, that some of your disks have high space usage and others are very low and it will cause your cluster health is no more all green. You will see a warning “vSAN Disk Balance” in your Skyline Health and this warning indicates that your cluster is imbalanced.
In order to distribute the load across disks for space usage, vSAN offers two types of rebalancing:
– Reactive Rebalancing, that occurs when vSAN detects a disk that is at 80% capacity or above and it will attempt to move data to other disks that are below this threshold. It is always automated and cannot be adjusted. If all disks are more than 80% utilized the Reactive Rebalance won’t run.
– Proactive Rebalancing, that occurs when vSAN detects that some of the disks are consuming a disproportionate amount of their capacity compared to other disks
So what causes this? Data can become imbalanced for many reasons: Storage policy changes, host or disk group evacuations, adding hosts, object repairs, or overall data growth. Normally, starting from vSAN 6.7 U3 you can automate all rebalancing activities with cluster-wide configuration and threshold activities, but if you still run some older versions of vSAN you can run manually initiate a rebalance of the objects in a vSAN cluster through vSAN Health plugin on vCenter GUI or through RVC console. If you trigger it through a vSphere Client you will experience that task stuck at 5% for hours, so there is an option to do it with Ruby Console where you can regularly check the status.
Log into the Ruby vSphere Console (RVC) and change to Computers namespace:
List your clusters or standalone hosts:
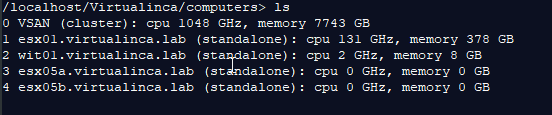
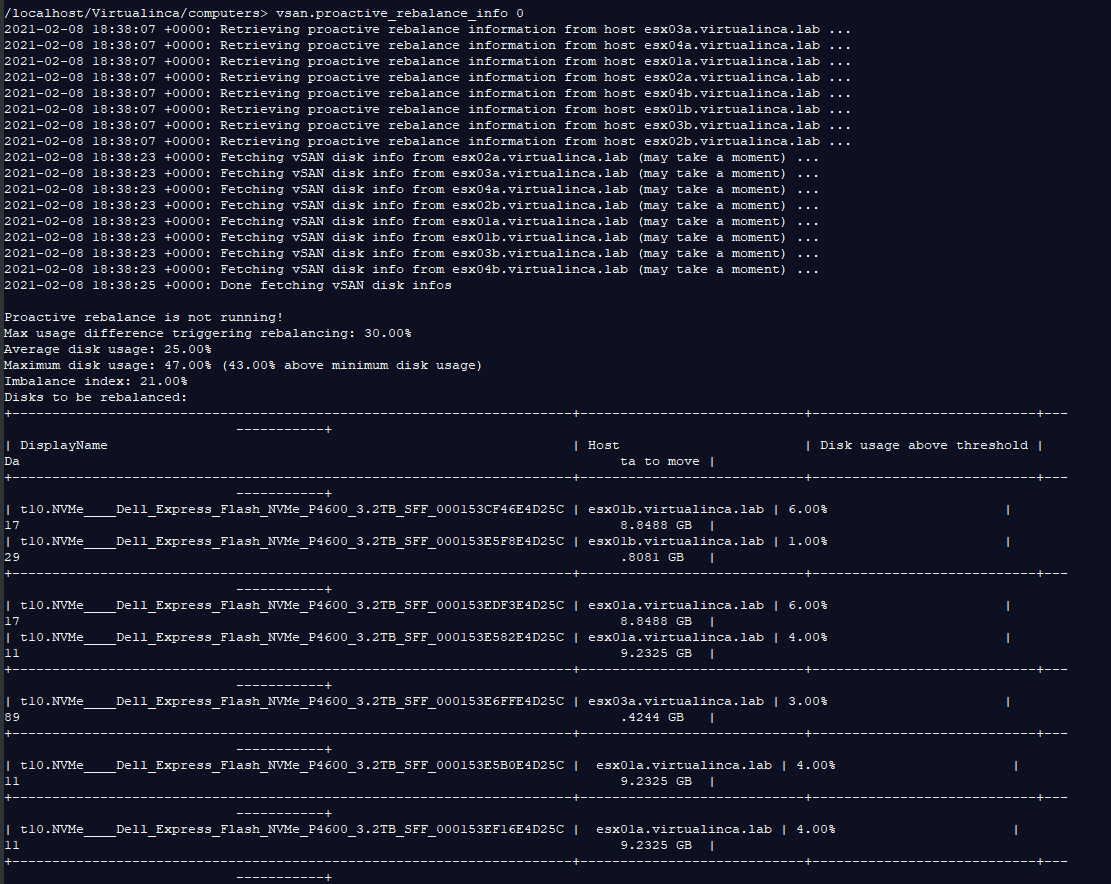
In my case, my vSAN cluster is named VSAN with a number 0. To see how much data needs to be rebalanced, Run this command on your vSAN cluster:
vsan.proactive_rebalance_info <vSAN-cluster-number, or “.” for current rvc path location>
The output will appear like this:
To start the rebalance, run this command:
vsan.proactive_rebalance_info -s <vSAN-cluster-number>
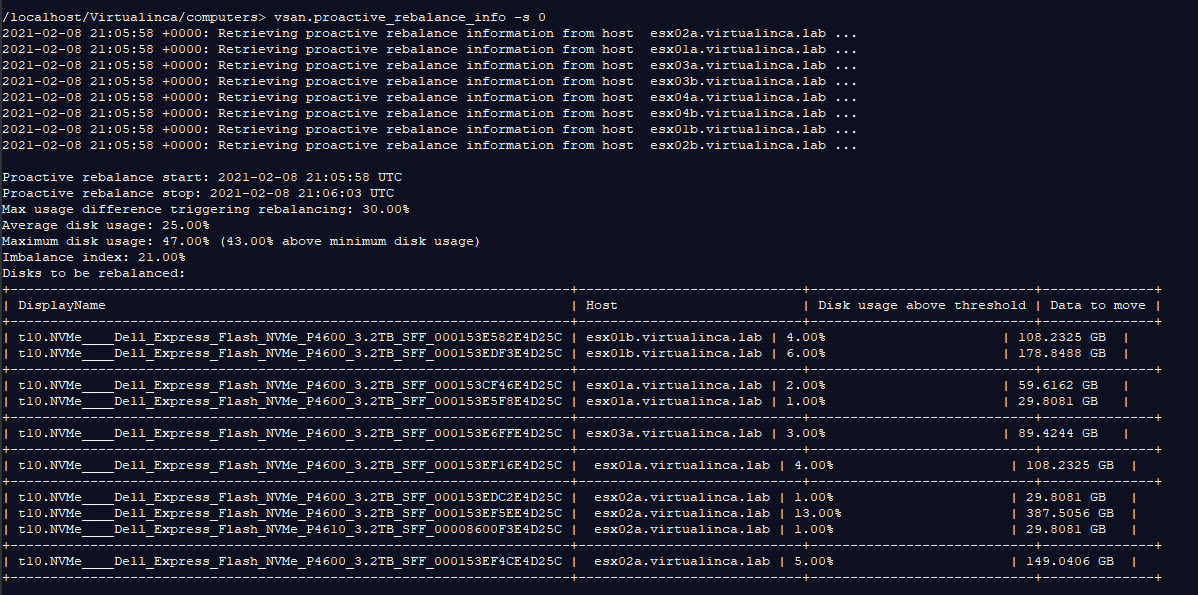
Proactive Rebalance starts, and you can monitor the status of the rebalance using this command:
vsan.proactive_rebalance_info <vSAN-cluster-number>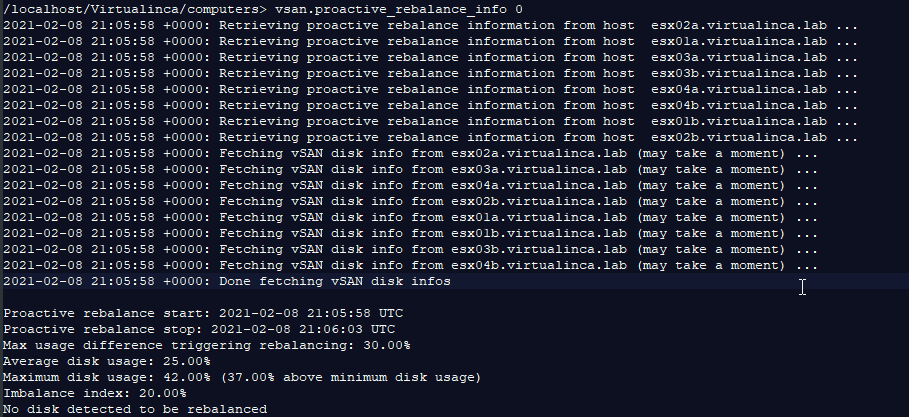
To run a rebalance beyond the default 24hrs, you will need to change the run times of the rebalance, with the values in units of seconds.
For example, setting the rebalance to run for a week:
vsan.proactive_rebalance . -t 604800
In which case this operation will run to completion or a week. If the rebalance finishes before the week is up, the process ends.